Generalized Linear Mixed Models (GLMM)
SUMMARY
Differences between SAS and R, (and even between different functions/procedures within same software) can lead to different results. These differences do not imply that one tool is more reliable than another but rather reflect variations in default settings and computational methods.
The following section summarizes the comparisons conducted using the dataset from “Gee Model for Binary Data” in the SAS/STAT Sample Program Library [1]. Each subsection corresponds to a different GLMM estimation method: Gaussian–Hermite Quadrature (GHQ), Laplace approximation, or Penalized Quasi‑Likelihood (PQL), and outlines the specific options and functions required to obtain consistent or comparable results across software platforms.
In general, different R functions were able to reproduce SAS GLMM results (using either GHQ or the Laplace approximation) when applying naïve or sandwich standard errors and assuming infinite degrees of freedom (ddff). However, only approximate agreement was achieved when comparing estimates based on the Between‑Within ddf. When using PQL, additional discrepancies emerged due to differences in the underlying estimation methods across software (i.e., PQL in R versus RSPL in SAS).
Gauss-Hermite Quadrature (GHQ) approximation
| S.E. | Ddff | SAS | R | Match? |
|---|---|---|---|---|
| Naive | Inf | GLIMMIX with ddff=none | lme4::glmer | Yes |
| Naive | Inf | GLIMMIX with ddff=none | GLMMadaptive::mixed_model | Aprox. |
| Naive | BW | GLIMMIX with ddff=BW (default) | lme4::glmer & parameters::dof_betwithin [1] | Aprox (1) |
| Sandwich | Inf | GLIMMIX with empirical option & ddff=none | lme4::glmer & merDeriv::sandwich | Aprox (2) |
| Sandwich | BW | GLIMMIX with empirical option & ddff=BW(default) | lme4::glmer, merDeriv::sandwich & parameters::dof_betwithin [1] | Aprox (1) |
BW: Between-Within, Inf: Infinite.
In R, the function
parameters::dof_betwithinuses a heuristic implementation of the between‑within method and therefore does not reproduce the exact results reported in Li and Redden (2015); instead, it yields values that are similar but not identical. In contrast, SAS computes the exact between‑within degrees of freedom.As
glmerdoes not provide cluster-level scores, thesandwichfunction cannot compute clustered robust estimatator, so it does not correspond to SAS’s emprical covariance [2].
Laplace approximation
| S.E. | Ddff | SAS | R | Match? |
|---|---|---|---|---|
| Naive | Inf | GLIMMIX with ddff=none | lme4::glmer | Aprox. (2) |
| Naive | Inf | GLIMMIX with ddff=none | glmmTMB::glmmTMB | Yes |
| Naive | BW | GLIMMIX with ddff=BW (default) | lglmmTMB::glmmTMB & parameters::dof_betwithin [1] | Aprox. (1) |
| Sandwich | Inf | GLIMMIX with empirical option & ddff=none | glmmTMB::glmmTMB & clubSandwich::vcovHC | Yes |
| Sandwich | BW | GLIMMIX with empirical option & ddff=BW(default) | lme4::glmer, merDeriv::sandwich & parameters::dof_betwithin [1] | Aprox (1) |
BW: Between-Within, Inf: Infinite.
(1): In R, the function parameters::dof_betwithin uses a heuristic implementation of the between‑within method and therefore does not reproduce the exact results reported in Li and Redden (2015); instead, it yields values that are similar but not identical. In contrast, SAS computes the exact between‑within degrees of freedom.
(2): Although lme4::glmer produced estimates consistent with SAS when using GHQ, it exhibited convergence issues that were not present in either SAS or glmmTMB::glmmTMB. After adjusting the optimization settings (see R section), only approximate agreement with the SAS results was achieved.
PQL
| S.E. | Ddff | SAS | R | Match? |
|---|---|---|---|---|
| Naive | Residual | GLIMMIX with method=RSPL & ddfm=residual | MASS::glmmPQL | Aprox. (1) |
(1): Results differ because of the different computation methods (PQL vs. RSPL)
GHQ
In this section, SAS and R results obtained under the GHQ approach are compared, after adjusting the necessary settings or applying additional functions to ensure alignment across software (See summary table above and respective R and SAS sections).
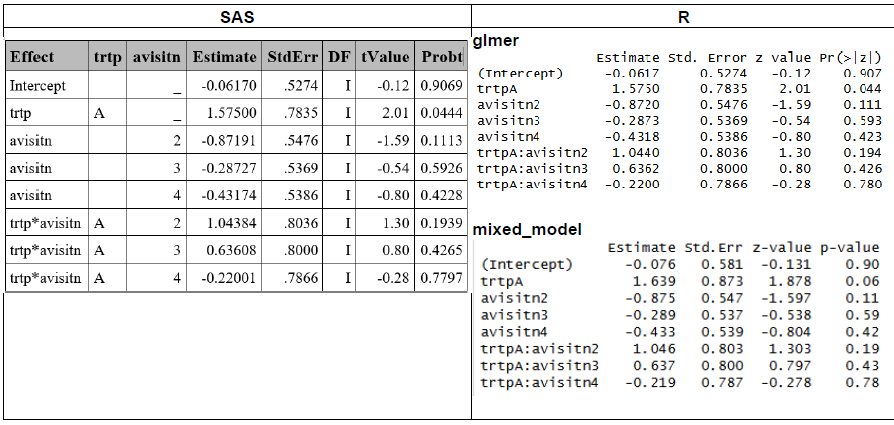
Model Based SE and Infinite ddff
Similar results in the estimate were obtained in SAS and R (using lme4::glmer), and approximated results were obtained with mixed_model (See R section for difference details between R functions).
Sandwich SE
Sandwich standard errors were computed using the EMPIRICAL option in SAS and the merDeriv::sandwich function in R (See corresponding SAS and R sections for details). This approach yielded comparable,though not identical results. The slight discrepancies arise because the base sandwich method cannot compute a fully cluster‑robust estimator for glmer models, and therefore does not reproduce the exact empirical covariance structure used by SAS [2].
Between-Within ddff were obtained in R using parameters::dof_betwithin function, which computes an approximation, instead of the exact dff as in SAS.
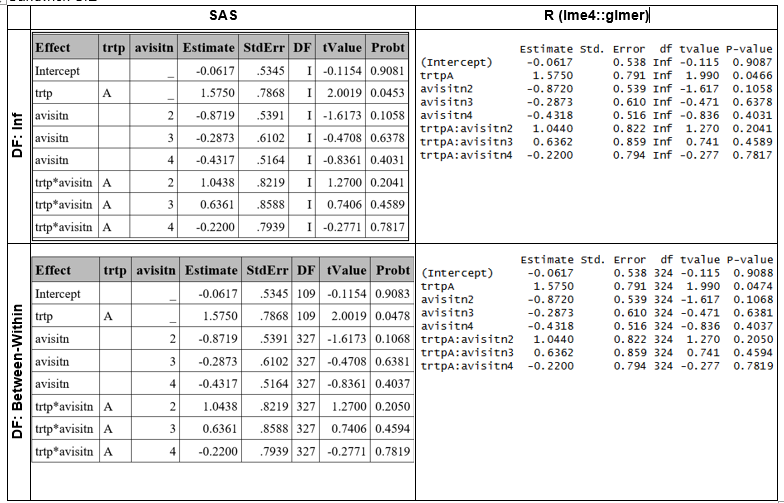
Laplace
Model Based SE and Infinite ddff
Results obtained with SAS and glmmTMB::glmmTMB matched, with minor differences in the latest decimal, attributable to different rounding between software.
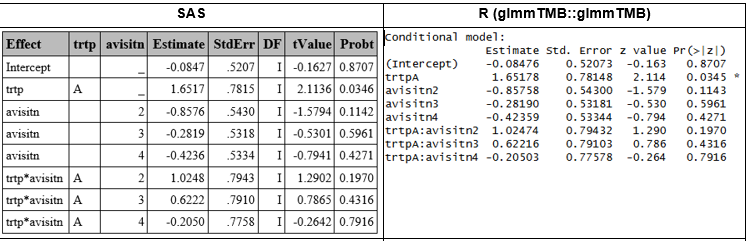
Sandwich SE
Sandwich SE were obtained using clubSandwich::vovHC R function, obtainng similar SE to SAS. However, there are differences in the between-within ddff, because the R function is based on a heuristic.
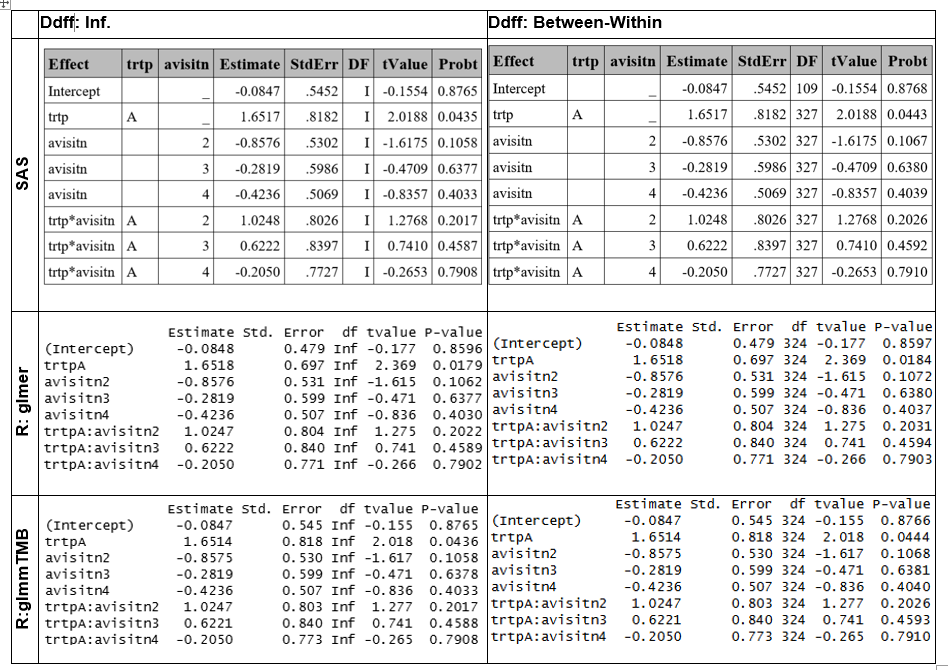
PQL
The PQL approach uses linear approximations instead of likelihood, making it less accurate for binary outcomes compared to the GHQ or Laplace methods described above. In SAS, this is implemented by default using the Residual Pseudo-Likelihood method (method=RSPL), which is a refinement of PQL which incorporates residual adjustments to better approximate the marginal likelihood, in the GLIMMIX procedure. In R the PQL computation can be obtained using the glmmPQL function form the MASS package.
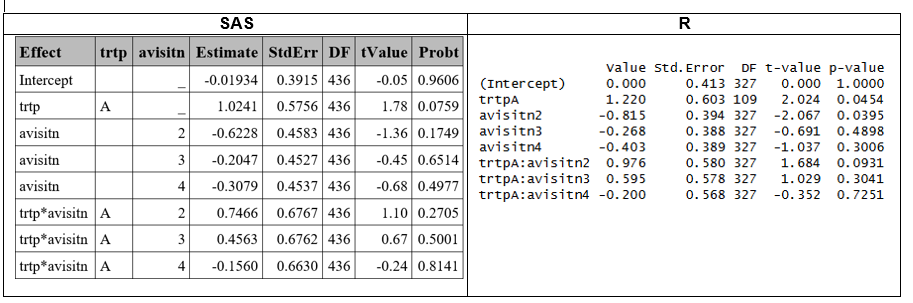
Results differ because of the different computation methods (PQL vs. RSPL) across software. Since glmmPQL is widely recognized as less reliable for binary outcomes, more robust approaches such as Laplace or GHQ are generally preferred. Consequently, further investigation using glmmPQL is not pursued.
OUTCOME WITH MORE THAN 2 CATEGORIES
Ordinal variables
A GLMM with ordinal outcome is fit in SAS using PROC CLIMMIX and function ordinal::clmm, (See corresponding SAS and R section for details), obtaining some differences in the results, because clmm applies different optimization algorithms (Newton, BFGS, NR methods) and its own parameterization of random effects [2].
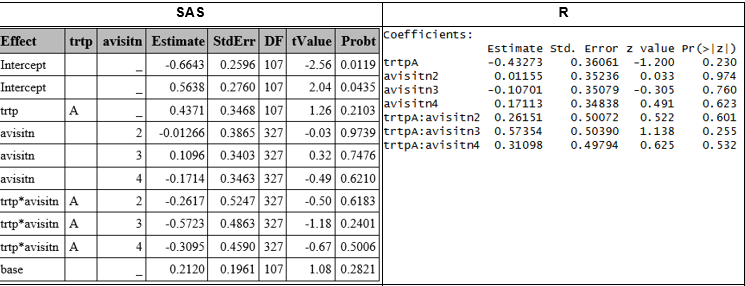
Nominal variables
GLMM with nominal outcome is created with GLIMMIX (See corresponding SAS section), However, no R functions equivalent to SAS’s GLIMMIX procedure have been identified for handling multinomial distributions in a frequentist framwork.
REFERENCES
[1] SAS Institute Inc.. SAS Help Center. The GEE procedure.
[2] Conceptual explanations were assisted using Microsoft Copilot (M365 Copilot, GPT‑5‑based model).
[5] Documentation of package parameters. dof_betwithin
[6] Brooks, M. E., et al. (2025). glmmTMB: Generalized Linear Mixed Models using Template Model Builder (Version 1.1.12) [R package manual]. The Comprehensive R Archive Network (CRAN). https://cran.r-project.org/web/packages/glmmTMB/glmmTMB.pdf
[7] Ordinal: Regression Models for Ordinal Data.