library(tidyverse)
library(survival) # for example data
library(logistf) # for firth regression
library(beeca) # for covariate adjustmentR vs SAS: Logistic Regression
Summary
Goal
Comparison of results between SAS vs R for different applications of logistic regression; where possible we try to ensure the same statistical method or algorithm is specified. However, there are some underlying differences between the algorithms in SAS vs R that cannot be (at least not easily) “tweaked”. The document also provides some remarks on what parameters to look out for and what could have caused the numerical differences.
Scope
Findings
Below are summary of findings from a numerical comparison using example data, where possible we specify the same algorithm in R and SAS.
In the following sections, the parameterisation of logistic regression implementation (with an without Firth option) will be compared followed by numerical comparison using example data.
Prerequisites
R packages
Data
Logistic regressions
We use the lung dataset provided with {survival} R package. Initial data preparation involves generating a new binary outcome based on the weight change.
# the lung dataset is available in ./data/lung_cancer.csv
lung2 <- survival::lung |>
mutate(
wt_grp = factor(wt.loss > 0, labels = c("weight loss", "weight gain"))
)
glimpse(lung2)g-computation
We use the trial01 dataset provided with {beeca} R package. Initial data preparation involves setting the treatment indicator as a categorical variable and removing any incomplete cases.
data("trial01")
trial01$trtp <- factor(trial01$trtp) ## set treatment to a factor
trial01 <- trial01 |>
filter(!is.na(aval)) ## remove missing data i.e complete cases analysis
# save the dataset to be imported in SAS
# write.csv(trial01, file = "data/trial01.csv", na = ".")Logistic Regression
Parameterisation Comparison
The following set of tables compare how to configure particular parameters / attributes of the methodologies.
| Attribute | SAS PROC LOGISTIC |
R stats::glm |
Description | Note |
|---|---|---|---|---|
| Likelihood optimization algorithm | Default | Default | Fisher’s scoring method (i.e., iteratively reweighted least squares (IRLS)) | For logistic regression, parameter estimates and covariance matrices estimated should be the same for both Fisher’s and Newton-Raphson algorithm for maximum likelihood. |
| Convergence criteria | Default | NA | Specifies relative gradient convergence criterion (GCONV=1E–8) | InPROC LOGISTIC there are three other convergence criteria which can be specified. However, there is no exact criterion that matches the criteria in stats::glm. |
| Convergence criteria | NA | Default | Specifies relative difference between deviance < 1E–8. | |
| Confidence interval (CI) estimation method | Default | confint.default() |
Wald CI | In stats::glm in R, function confint.default() gives the Wald confidence limits; whereas function confint() gives the profile-likelihood limits. |
| Hypothesis tests for regression coefficients | Default | Default | Wald tests, which are based on estimates for the regression coefficients and its corresponding standard error. |
Numerical Comparison
Every effort is made to ensure that the R code employs estimation methods/ optimization algorithms/ other components that closely match (as much as possible) those used in the SAS code.
glm in R
Note, the default fitting method in glm is consistent with the default fitting method in PROC LOGISTIC procedure.
- Default fitting method in
glmis iteratively reweighted least squares, and the documentation can be found here. - Default fitting method for
PROC LOGISTICprocedure is Fisher’s scoring method, which is reported as part of the SAS default output, and it is equivalent to “Iteratively reweighted least squares” method as reported in this documentation.
m1 <- stats::glm(
wt_grp ~ age + sex + ph.ecog + meal.cal,
data = lung2,
family = binomial(link = "logit")
)
# model coefficients summary
summary(m1)$coefficientsNote, function confint.default gives the Wald confidence limits, which is the default option in SAS PROC LOGISTIC procedure; whereas confint gives the profile-likelihood limits. Conditional odds ratio is calculated by taking the exponential of the model parameters.
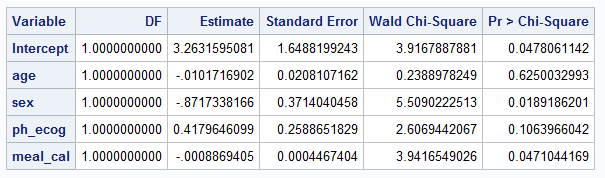
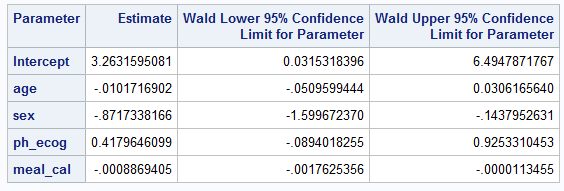
cbind(est = coef(m1), confint.default(m1))PROC LOGISTIC in SAS (without firth option)
PROC LOGISTIC DATA=LUNG2; # import lung
MODEL WT_GRP(EVENT="weight_gain") = AGE SEX PH_ECOG MEAL_CAL;
ods output ESTIMATEs=estimates;
run;Below is screenshot of output tables summarizing coefficient estimates and confidence intervals
Firth logistic regression
The following set of tables compare how to configure particular parameters / attributes of the methodologies.
Parameterisation Comparison
| Attribute | SAS PROC LOGISTIC w/ Firth option |
R logistf::logistf |
Description | Note |
|---|---|---|---|---|
| Likelihood optimization algorithm | Default | control =logistf.control (fit =“IRLS”) |
Fisher’s scoring method (i.e., iteratively reweighted least squares (IRLS)) | |
| Likelihood optimization algorithm | TECHNIQUE = NEWTON |
Default | Newton-Raphson algorithm | |
| Convergence criteria | Default | NA | Specifies relative gradient convergence criterion (GCONV=1E–8). | InPROC LOGISTIC there are three other convergence criteria which can be specified. If more than one convergence criterion is specified, the optimization is terminated as soon as one of the criteria is satisfied. |
| Convergence criteria | NA | Default | Specifies three criteria that need to be met: the change in log likelihood is less than lconv (default is 1E-5), the maximum absolute element of the score vector is less than gconv (default is 1E-5), and the maximum absolute change in beta is less than xconv (default is 1E-5). | The gconv criteria in logistif is different from GCONV in SAS. The lconv criteria is also not exactly the same as the ABSFCONV or FCONV in PROC LOGISTIC in SAS, although the criteria use log likelihood. However, the xconv in R and XCONV in SAS seems to be consistent. |
| Convergence criteria | XCONV = 1E–8 |
control = logistf.control( xconv = 1E–8, lconv = 1, gconv = 1) |
Specifies the maximum absolute change in beta < 1E–8. | In logistf, three convergence criteria are checked at the same time. So here we use a large convergence criteria value for lconv and gconv to mimic the scenario where only xconv is checked. |
| Confidence interval (CI) estimation method | Default | pl= FALSE |
Wald CI | For logistf: “Note that from version 1.24.1 on, the variance-covariance matrix is based on the second derivative of the likelihood of the augmented data rather than the original data, which proved to be a better approximation if the user chooses to set a higher value for the penalty strength.” This could cause differences in standard error estimates in R vs SAS for Firth logistic regression, and consequently results in differences in the corresponding Wald CI estimates and hypothesis tests results (e.g., p-values). |
| Confidence interval (CI) estimation method | CLPARM = PL CLODDS = PL |
Default | Profile likelihood-based CI | For Firth’s bias-reduced logistic regression, it makes more sense to use penalized likelihood-based CI so it is consistent with the parameter estimation method which uses penalized maximum likelihood. |
| Hypothesis tests for regression coefficients | Default | pl= FALSE | Wald tests, which are based on estimates for the regression coefficients and its corresponding standard error. | |
| Hypothesis tests for regression coefficients | NA | Default | “Likelihood ratio tests”, which are based on profile penalized log likelihood. | In SAS, when the model statement option CLPARM = PL is specified, the CI will be calculated based on profile likelihood. However, the hypothesis testing method is still a Wald method. This could cause results mismatch in the p-value. |
Numerical Comparison
Note that while Firth logistic regression is not required for our example dataset nonetheless we use it for demonstration purposes only.
logistf in R
By default, the convergence criteria in
logistfspecifies that three criteria need to be met at the same time, i.e., the change in log likelihood is less than lconv (default is 1E-5), the maximum absolute element of the score vector is less than gconv (default is 1E-5), and the maximum absolute change in beta is less than xconv (default is 1E-5). In SAS, the default convergence criteria inPROC LOGISTICspecifies relative gradient convergence criterion (GCONV=1E–8); while SAS also support three other convergence criteria but when there are more than one convergence criterion specified, the optimization is terminated as soon as one of the criteria is satisfied. By looking at the R pacakge/SAS documentation, thegconvcriteria inlogistiffunction is different from theGCONVin SAS. Thelconvcriteria is also not exactly the same as theABSFCONVorFCONVin PROC LOGISTIC in SAS, although the criteria use log likelihood. However, similar convergence criteria might be obtained by using the maximum absolute change in parameter estimates (i.e.,xconvin R and SAS). Therefore, for comparison with the SAS output, inlogistffunction, we use a large convergence criteria value forlconvandgconvto mimic the scenario where onlyxconvis checked, i.e., specifylogistf.control(xconv = 0.00000001, gconv = 1, lconv = 1)for thecontrolargument.By default,
logistffunction in R computes the confidence interval estimates and hypothesis tests (including p-value) for each parameter based on profile likelihood, which is also reported in the output below. However, Wald method (confidence interval and tests) can be specified by specifying thecontrolargument withpl = FALSE.
firth_mod <- logistf(
wt_grp ~ age + sex + ph.ecog + meal.cal,
data = lung2,
control = logistf.control(
fit = "IRLS",
xconv = 0.00000001,
gconv = 1,
lconv = 1
)
)
summary(firth_mod)$coefficients
## Code below would give Wald CI and tests results by adding `pl = FALSE`
# logistf(..., pl = FALSE)Note, function confint gives the profile-likelihood limits. Given the parameters from Firth’s bias-reduced logistic regression is estimated using penalized maximum likelihood, confint function is used. Conditional odds ratio is calculated by taking the exponential of the model parameters.
cbind(est = coef(firth_mod), confint(firth_mod))PROC LOGISTIC in SAS (with firth option)
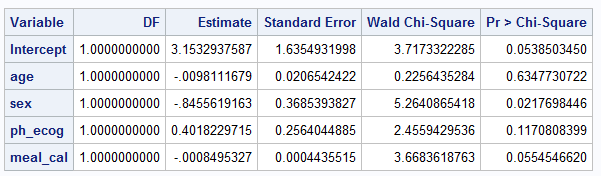
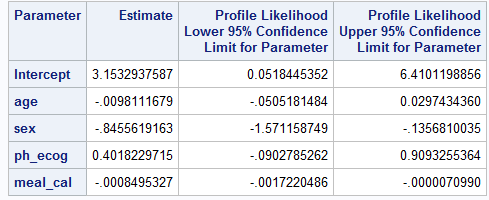
Note, by default, SAS computes confidence interval based on Wald tests. Given the parameters from Firth’s method is estimated using penalized maximum likelihood, below specifies CLODDS = PL CLPARM=PL (based on profile likelihood), which is consistent with the maximization method and the R code above. However, the default hypothesis test for the regression coefficients is still a Wald test, and the Chi-square statistics is calculated based on coefficient estimate and its corresponding standard error.
XCONVspecifies relative parameter convergence criterion, which should correspond to thexconvinlogistffunction in R. We specifyXCONV = 0.00000001so it should be consistent with the R code above.
PROC LOGISTIC DATA=LUNG2;
MODEL WT_GRP(EVENT="weight gain") = AGE SEX PH_ECOG MEAL_CAL / firth
clodds=PL clparm=PL xconv = 0.00000001;
ods output ESTIMATEs=estimates;
run;Below is screenshot of output tables summarizing coefficient estimates and it’s 95% CI
g-computation with covariate adjustment
We compare two implementions of g-computation in SAS:
- The “Predictive margins and average marginal effects” %margins macro. The %margins macro uses “the delta method […] to determine the standard errors for predictive margins and marginal effects”. Note that the %margins macro uses the
PROC GENMODprocedure to implement the working logistic regression model and require another macro %NLEST to calculate contrasts that requires delta methodl such as risk ratio or odds ratio. - The SAS code provided in the appendix of the Ge et al. (2011) implements the method outlined in the associated paper and simulations. Note: the Ge et al. (2011) macro uses the
PROC LOGISTICprocedure to implement the working logistic regression model.PROC IMLis used to calculate the delta method to determine the standard errors.
Numerical Comparison
get_marginal_effect in R
We fit a logistic regression model with covariate adjustment to estimate the marginal treatment effect using the delta method for variance estimation: as outlined in Ge et al (2011).
## fit the model including model based variance estimation with delta method
fit1 <- stats::glm(aval ~ trtp + bl_cov, family = "binomial", data = trial01) |>
beeca::get_marginal_effect(
trt = "trtp",
method = "Ge",
contrast = "diff",
reference = "0",
type = "model-based"
)
"Marginal treatment effect"
fit1$marginal_est
"Standard error"
fit1$marginal_se%Margins macro in SAS
We now use the SAS %Margins macro to perform the Ge et al. (2011) method on trial01 to estimate the marginal risk difference and it’s standard error.
%Margins(data = myWork.trial01,
class = trtp,
classgref = first, /*Set reference to first level*/
response = avaln,
roptions = event='1', /*Ensure event is set to 1 = Yes */
dist = binomial,
model = trtp bl_cov,
margins = trtp,
options = cl diff reverse, /*Specify risk difference contrast and
direction of treatment effect is correct*/
link = logit); /*Specify logit link function */
** Store output data sets ;
data myWork.margins_trt_estimates;
set work._MARGINS;
run;
data myWork.margins_trt_diffs;
set work._DIFFSPM;
run;
%LR macro in SAS (Ge et al, 2011)
%LR(data = myWork.trial01, /* input data set */
var1 = bl_cov, /* continuous covariates in the logistic regression */
var2 = trtp, /* categorical covariates in the logistic regression */
p1 = 1, /* number of continuous covariates in the logistic regression */
p2 = 1, /* number of categorical covariates in the logistic regression */
resp = avaln, /* binary response variable in the logistic regression */
ntrt = 1); /* position of the treatment variable in the categorical covariates */
data myWork.ge_macro_trt_diffs;
set work.geout;
run;
Final remarks
In summary, there are a few things to be aware of when comparing logistic regression results in R vs SAS. It is crucial to carefully manage the input parameters for each model to ensure they are configured similarly for logistic regression analyses. As highlighted also in Logistic Regression in SAS, the variable parameterization is also important for modelling and interpretation, ensuring the types of variable (continuous vs. categorical) and reference values of categorical variable are applied as expected.
- Likelihood optimization method
The default likelihood optimization method in
glmandPROC LOGISTICis the same (i.e., Fisher’s scoring method or iteratively reweighted least squares (IRLS)).However, the default optimization method in
logistfis Newton-Raphson, which can be modified into IRLS viacontrol = logistf.control(fit = “IRLS”). Alternatively, one could specifytechnique = newtonin the model statement in SAS to modify the likelihood optimization method.
- Convergence criteria
Although both SAS and R allows options to modify the convergence criteria, the criteria does not seem to be exactly the same, which could cause results mismatch in some scenarios.
The default convergence criteria in
PROC LOGISTICspecifies the relative gradient convergence criterion; where the default convergence criteria inglmspecifies relative difference between deviance.The default setting in logistf have checked more than one convergence criterion in its algorithm (i.e., change in log likelihood, derivative of the log likelihood and parameter estimates). One could specify a very large value for two of the criteria in order to mimic the scenario where only one criterion is checked (e.g.,
control = logistf.control (xconv = 0.00000001, lconv = 1, gconv = 1) inlogistfin R should be consistent to the option ofxconv = 0.00000001in SAS).
- Confidence interval
The
confint()function in R will computes profile likelihood based CI forglmfitted model. However, in SAS, the default confidence interval is Wald CI. To match the default CI calculation in SAS forglmfitted model, useconfint.default()function in R.Nevertheless, Firth’s biased-reduced logistic regression estimates parameter using penalized maximum likelihood, it makes more sense to use
confint()function forlogistffitted model. In the meantime, in SAS, when fitting a Firth’s logistic regression, it is also better to specify the model statement optionclparm = plwhich will also generate profile penalized likelihood CI.We shall note that in the Firth logistic regression numerical example, the estimated standard errors does not match, but the CIs match at 0.001 level. This is because the CI was estimated based on profile penalized likelihood in R and SAS, and please see the next discussion point for potential reasons about differences between the estimated standard error. (I have compared Wald CIs estimated in R vs SAS, which could not match. This make sense as Wald CIs are calculated based on the estimated standard errors.)
- Hypothesis test and p-value
The default hypothesis tests for the regression coefficients are the same in
glmandPROC LOGISTIC, which are both Wald tests and calculated based on estimates for the regression coefficients and its corresponding standard error.As for
logistffunction, the default hypothesis testing method is based on profile penalized log likelihood (source code here). And it was noted in the R documentation that, “from version 1.24.1 on, the variance-covariance matrix is based on the second derivative of the likelihood of the augmented data rather than the original data, which proved to be a better approximation if the user chooses to set a higher value for the penalty strength.” This could cause difference in the estimate of standard error in R vs SAS for Firth logistic regression, and consequently results in differences in the corresponding Wald CI estimates and hypothesis tests results (e.g., p-values).Wald method can be used in a
logistffunction in R by specifyingpl = FALSEin thecontrolargument, which should correspond to the method used in SAS to calculate p-value. However, when specifyingpl = FALSE, the CI is also calculated using Wald method.
Reference
- A relevant blog here (check comments in the blog).
- PROC LOGISTIC statement documentation in SAS.
- Reference manual for
logistfpackage in R. - GitHub repository for
logistfpackage in R. - GitHub repository for a SAS procedure about Firth logistic regression authored by the author of
logistfR package, which was based on PROC IML instead of PROC LOGISTIC and was probably authored before the availability of Firth option in PROC LOGISTIC statement in SAS. - Ge, Miaomiao, et al. “Covariate-adjusted difference in proportions from clinical trials using logistic regression and weighted risk differences.” Drug information journal: DIJ/Drug Information Association 45 (2011): 481-493.
- SAS Institute Inc. “Predictive margins and average marginal effects.” (Last Published: 13 Dec 2023)
Comment on model selection
As indicated in Logistic regression in R and Logistic regression in SAS, the chi-Sq test statistics and p-values are different when performing model selections in R vs. SAS. The reason for this discrepancy is that the chi-Sq statistics from
anova()in R is based on deviance test using residual deviance while the chi-Sq statistics fromPROC LOGISTICw/SELECTIONoption in SAS is based on Wald test using z-values squared.Exact match (at 0.001 level) can be obtained using
glmin R vsPROC LOGISTICprocedure (without Firth option) in SAS, for coefficient estimates, 95% CI, and for p-value.